I have a lousy memory but a fabulous database system.
Wolf Trap Opera gets frequent inquiries about the tools and processes we use to track the thousands of singers who audition for our company. The answer? A robust Filemaker Pro database.
I’ve suffered unhappily through forced usage of Access, Quark and other clunky database programs. Unlike these cousins, Filemaker is customizable, elegant and versatile. Its capabilities far outreach what most of us need, but it is increasingly easy to use on an entry level, and it can grow with you.
The street price is $329, but the best thing is that Filemaker is available for “qualified education and Non-Profit institutions, organizations and end users” at just $197. Not pennies, I know. But well worth it. I’ve been using it since 1994, and I have gotten more value from this product that from any other except the MS Office suite. There’s even a mobile app for iOS (Apple recently acquired Claris, Filemaker’s creator).
Today, we’ll take a look at the ways in which a program like Filemaker can help with data consolidation and retrieval. The first step is to take a look at your information and understand how it should be organized; once you understand how a database program thinks, it’s simple to make the migration. I’ll use our auditions DB as an example.
Records and Fields and Layouts, oh my!
Think of your information in these three basic ways:
Records are individual sets of data, all of which have a unique ID. In our case, that ID is the singer’s email address, since our online application system uses email as its identifier. You could use first and last name if that’s easier. Each record contains a bunch of individual data points in things called fields. (If you’re used to putting your info in spreadsheets, think of a record as a row or column, and a field as an individual cell.) In our case, each singer’s record has almost a hundred fields – everything from background information to previous audition comments to arias and roles sung.
Fields contain specific information about each record. Fields can be formatted as text entry, checkboxes or radio buttons, dates/times, numbers, and more. The biggest piece of advice I can give in your thinking about fields is that they should be as finely tuned and microscopic as possible. Drill your data down to its smallest unit so that it’s easier to manipulate (sort, filter, etc) later. Simplest example: Instead of an address field, create individual fields for street, city, state, zip.
Layouts are simply ways of arranging and viewing your data. Similar to hiding rows in spreadsheets, but far more satisfying.
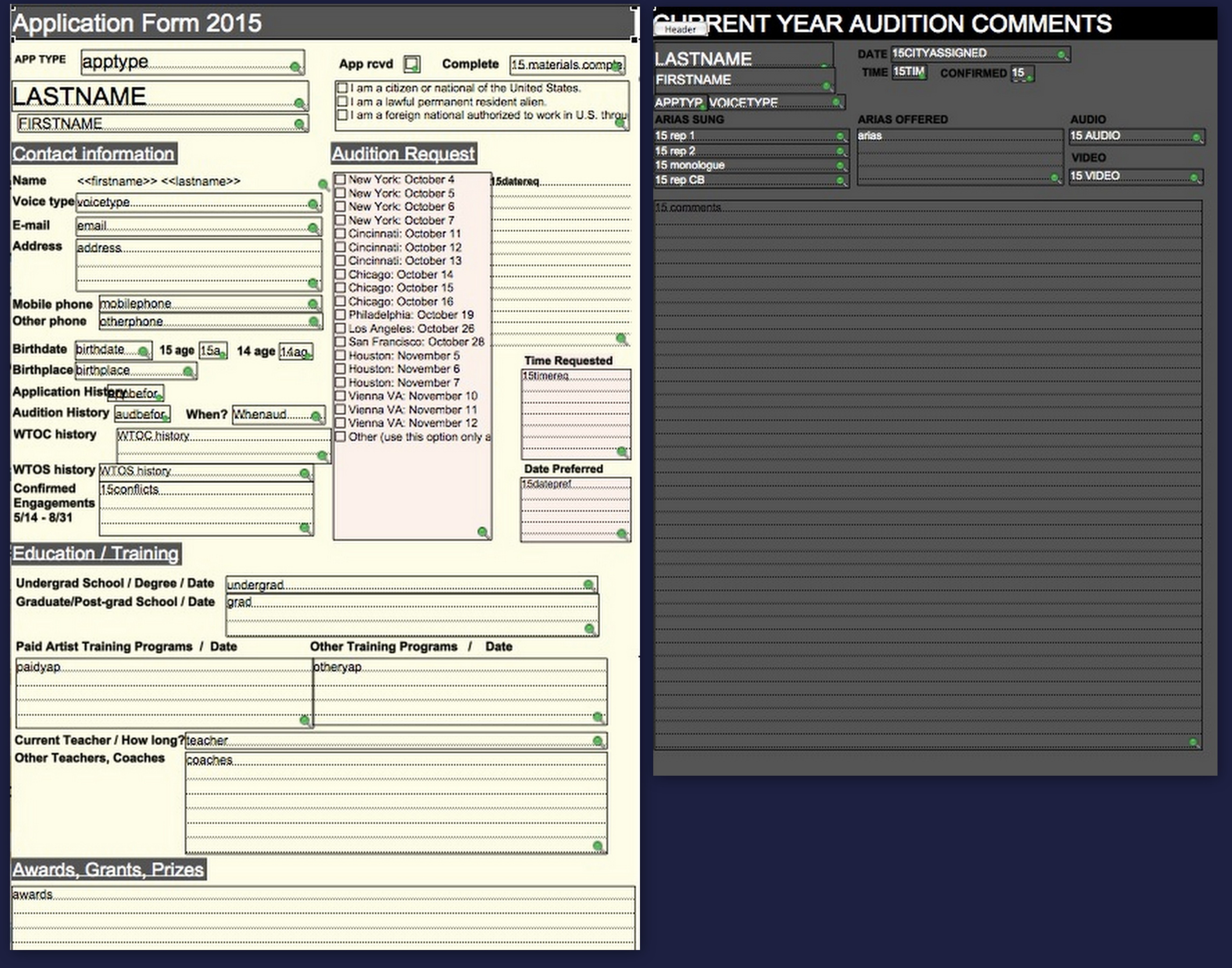
This is where the beauty of the tool shows through. Once I find a certain record (in this case, a record = an individual artist), I can view that person’s application form, audition comments, background info, etc – all in individualized layouts designed to show what I want and ignore the rest. I can also find a whole bunch of records (say, for example, multiple singers in a single voice type or those auditioning in a specific city) and compare their basic data in a streamlined list format.
Not As Geeky As It Sounds
If you’re already in the database cult, none of this is revolutionary. But I’m continually surprised at how many arts organizations limp by with archaic legacy non-systems (like endless Word docs or unwieldy spreadsheets… or worse.) If you think a database system holds potential for your organization but you’re not ready to make the leap just yet, it’s not too late to start thinking the way databases think. Spreadsheets that are organized effectively (with a single row per “record” and a single discrete type of data in each “field”) are a good first step and are easily imported into your database once you get it up and running!
Thank you for the authoritative read on this issue. To me, being able to actually see the icon in the…